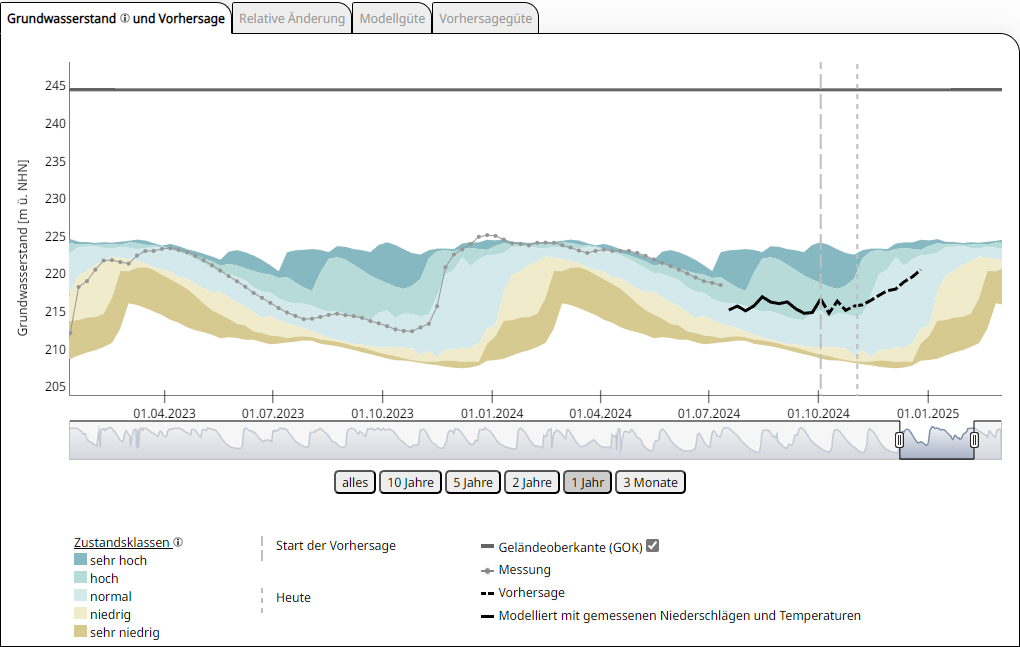
Grundwasserstandsvorhersagen prognostizieren, wie der Grundwasserstand an einem bestimmten Ort zu einem bestimmten Zeitpunkt sein wird. Grundlage für die Vorhersagen sind die aktuellen Grundwasserstände, die Grundwasserstände der Vergangenheit und die für einen zukünftigen Zeitraum zu erwartenden Niederschläge und Temperaturen. Die Vorhersagen werden mit Hilfe von mathematischen Modellen, in diesem Fall einem datengetriebenen statistischen Vorhersagemodell mit künstlichen neuronalen Netzen und maschinellem Lernen, erstellt und können zur Warnung vor möglichen Hoch- oder Niedrigwasserständen und damit zur Planung von wasserwirtschaftlichen Maßnahmen genutzt werden.
Vorhersagen des Grundwasserspiegels können ein wichtiges Instrument für ein nachhaltiges Grundwassermanagement sein. In der Landwirtschaft können sie dazu dienen, rechtzeitig auf schwindende Grundwasserressourcen hinzuweisen, um die Bewässerung von Feldern zu optimieren und den Wasserverbrauch zu reduzieren. Auch im Bauwesen oder bei der Planung von Infrastrukturprojekten können sie eingesetzt werden, um das Risiko von Überschwemmungen und Schäden an Gebäuden, Straßen und Brücken zu minimieren. Darüber hinaus können Grundwasserstandsvorhersagen die interessierte Öffentlichkeit für möglicherweise bevorstehende Dürreperioden mit niedrigen Grundwasserständen, aber auch für Überflusssituationen mit hohen Grundwasserständen sensibilisieren.
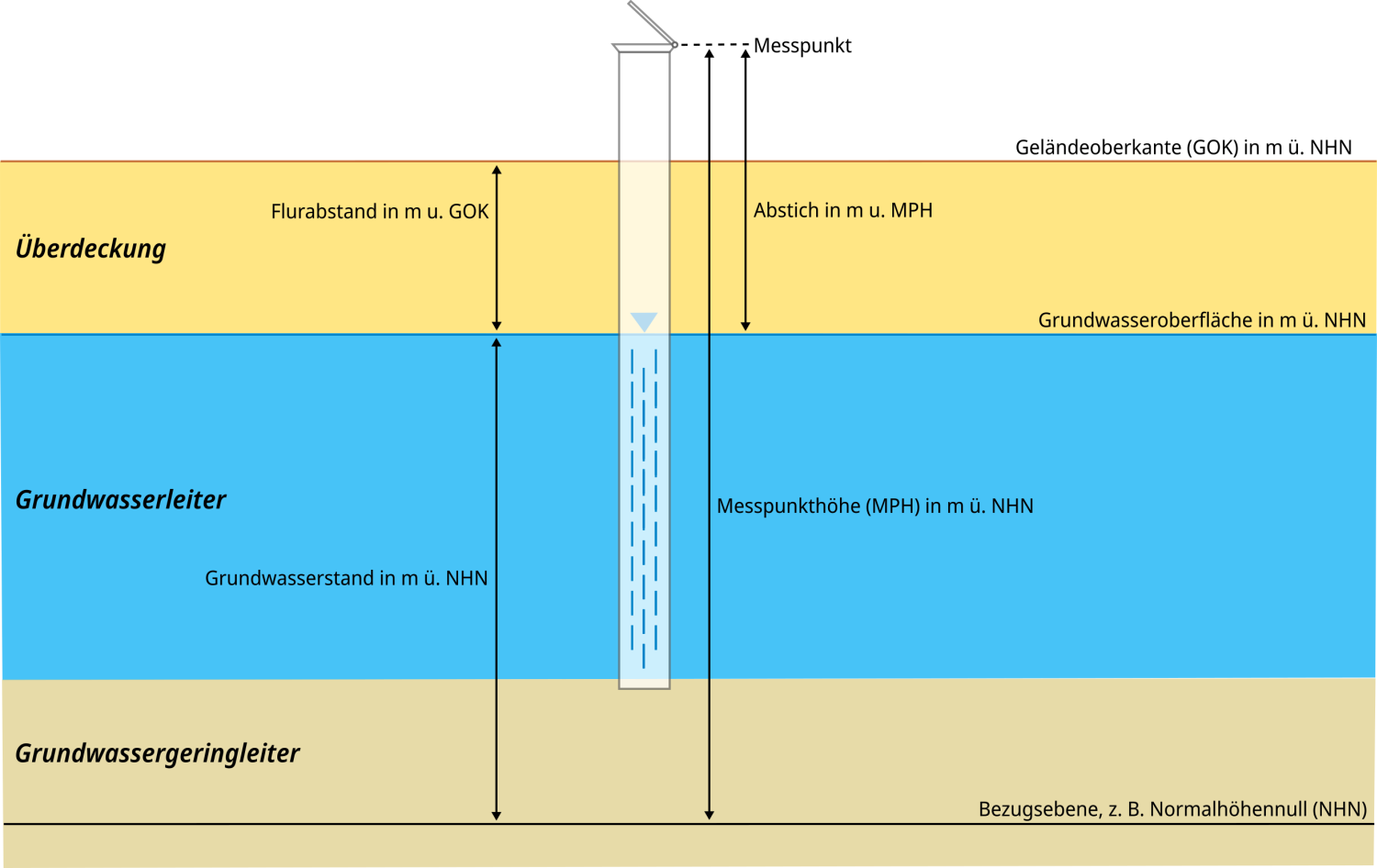
Der Grundwasserstand gibt nach DIN 4049-3 die Höhe des Grundwasserspiegels über oder unter einer waagerechten Bezugsebene an,
in der Regel über Normalhöhennull oder unter Geländeoberkante. Umgangssprachlich werden die Begriffe Grundwasserstand und
Grundwasserspiegel häufig synonym verwendet. Nach der o. g. Norm wird der Grundwasserspiegel als die druckmäßig ausgeglichene
Grenzfläche des Grundwassers gegen die Atmosphäre definiert.
Der Grundwasserspiegel in einem Brunnen oder einer Messstelle kann als Grundwasserstand in Metern über Normalhöhennull
(m ü. NHN), als Flurabstand in Metern unter Geländeoberkante (m u. GOK) oder als Abstich in Metern unter Messpunkthöhe
(m u. MPH) angegeben werden.
Schematische Abbildung einer Grundwassermessstelle und Darstellung gebräuchlicher Messgrößen zum Grundwasserstand. Quelle: BGR
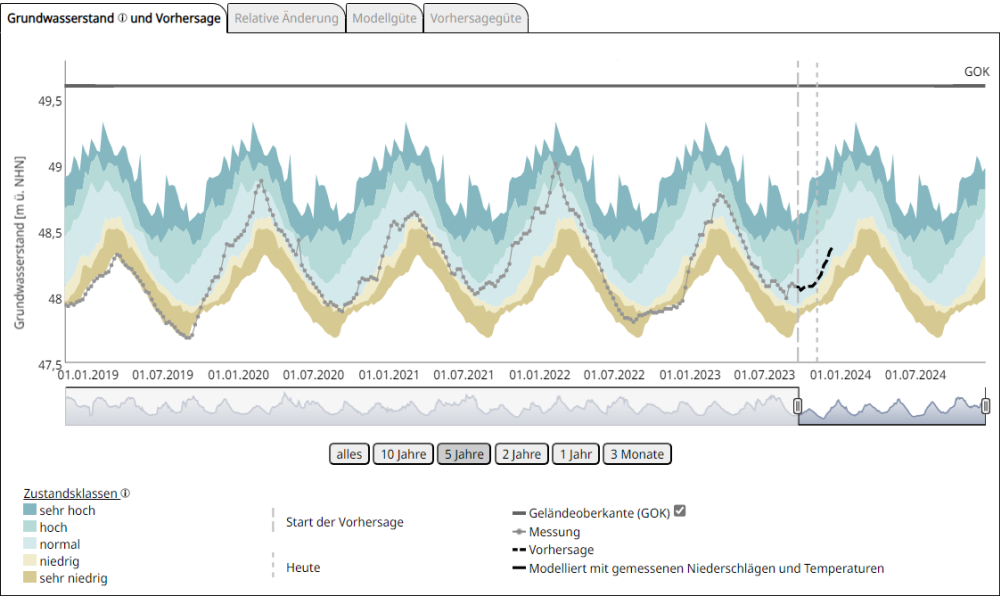
Wird der Grundwasserstand an einer Messstelle über einen längeren Zeitraum gemessen, kann das Ergebnis grafisch in Form einer Grundwasserstandsganglinie dargestellt werden. In Karten lässt sich der Grundwasserstand als Punktinformation oder in Form von Grundwasserhöhengleichen (auch Grundwasserisohypsen) darstellen. Dabei kann der Grundwasserstand zu einem bestimmten Stichtag, als Mittelwert über einen definierten Zeitraum oder auch als Schwankungsbreite über einen bestimmten Zeitraum wiedergegeben werden.
Grundwasserstandsganglinie einer Messstelle über den Zeitraum von 5 Jahren sowie Vorhersage für 3 Monate. Um die Grundwasserstände einzuordnen, werden alle mittleren wöchentlichen Grundwasserstände aus dem 30-jährigen Referenzzeitraum 1991 - 2020 in fünf Klassen unterteilt und als Hintergrund farbig abgestuft abgebildet. Dabei bedeutet "sehr niedrig" < 10 % aller Werte, "niedrig" zwischen 10 und 25 % aller Werte, "normal" zwischen 25 und 75 % aller Werte, "hoch" zwischen 75 und 90 % aller Werte und "sehr hoch" > 90 % aller Werte der jeweiligen Kalenderwoche von 1991 - 2020. Quelle: BGR
Die zeitliche Beobachtung der Grundwasserstände ist wichtig, um problematische Veränderungen rechtzeitig zu erkennen und gegebenenfalls Gegenmaßnahmen einleiten zu können, um negative Auswirkungen auf die Ressource Grundwasser bzw. durch das Grundwasser zu verhindern. So kann ein Absinken des Grundwasserspiegels zu einer Beeinträchtigung von grundwasserstandsabhängiger Vegetation und zu Bauwerksschäden durch Setzungen führen. Ein Anstieg des Grundwassers wiederum kann ebenso Schäden an Bauwerken verursachen oder im Extremfall landwirtschaftliche Nutzflächen unbrauchbar machen.
Der Grundwasserstand kann in (ungenutzten) ausgebauten Bohrbrunnen, in nicht verrohrten Festgesteinsbohrungen und in gegrabenen Brunnen
oder natürlichen Gruben gemessen werden. Im Idealfall wird er in einer zu diesem Zweck errichteten Grundwassermessstelle ermittelt.
Traditionell wurde der Grundwasserstand manuell mittels eines Lichtlots festgestellt.
Heutzutage werden meist automatische Messstationen eingesetzt, in denen der Grundwasserstand kontinuierlich mittels eines Drucksensors
gemessen und auf einem Datenlogger gespeichert wird, der in regelmäßigen Abständen von Mitarbeitern vor Ort besucht und ausgelesen wird.
Häufig besteht die Möglichkeit einer Datenfernübertragung und die Daten werden über das Mobilfunknetz an die dafür zuständige Behörde
übermittelt und können in Echtzeit dargestellt werden.
Messung des Grundwasserstands mittels eines Lichtlots während einer Grundwasserprobenahme. Quelle: BGR
Grundwassermessstelle in den Seeländereien. Zum Schutz vor Vandalismus befinden sich alle Bauteile (inkl. DFÜ-Funktionalität per GPRS) unterhalb einer Standardpegelklappe. Quelle: BGR
Um natürliche und möglichst unbeeinflusste Grundwasserstände zu messen, sollten Messstellen ausgewählt werden, an denen die
Grundwasseroberfläche nicht oder so wenig wie möglich von Grundwasserentnahmen wie beispielsweise durch Wasserwerksbrunnen oder
Beregnungsbrunnen der Landwirtschaft beeinflusst ist.
Der Grundwasserspiegel in einem Grundwasserleiter wird gesteuert durch das Verhältnis von Neubildung, Speicherung und Abfluss.
Physikalische Eigenschaften wie die Porosität, Durchlässigkeit und Mächtigkeit der Gesteine, aus denen der Grundwasserleiter
aufgebaut ist, beeinflussen dieses System. Das Gleiche gilt für klimatische und hydrologische Faktoren, wie der Zeitpunkt und
die Menge der Neubildung durch Niederschlag, Abfluss aus dem Untergrund in Oberflächengewässer und die Evapotranspiration.
Wenn die Neubildungsrate eines Grundwasserleiters die Abflussrate übersteigt, steigen die Wasserstände. Im umgekehrten Fall,
wenn die Grundwasserentnahme oder -abgabe größer ist als die Grundwasserneubildung, wird das im Aquifer gespeicherte Grundwasser
aufgezehrt und die Wasserstände sinken.
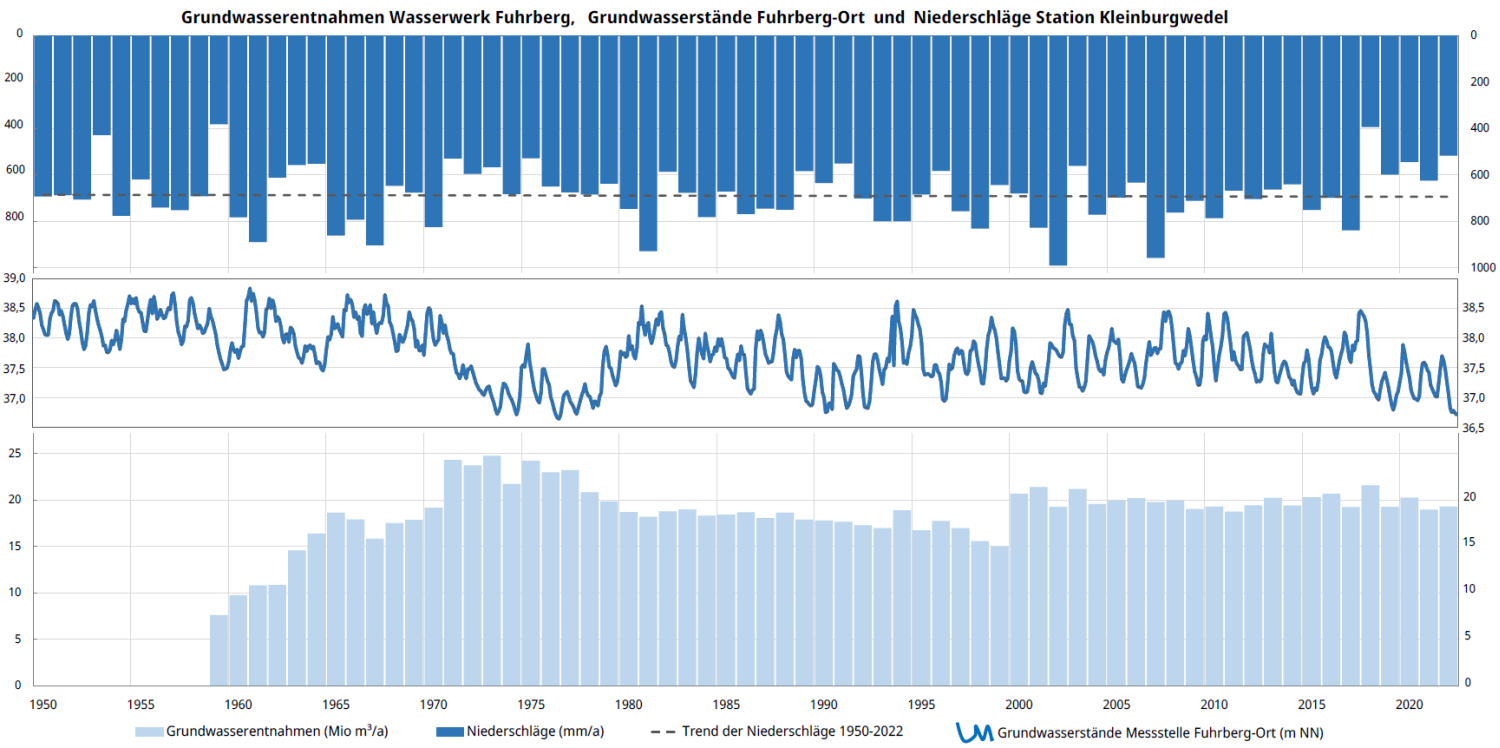
Die Wasserstände in vielen Grundwasserleitern in Deutschland folgen einem natürlichen jahreszeitlichen Muster. Typischerweise steigen sie im Winter und Frühjahr aufgrund höherer Niederschläge und Grundwasserneubildung an, während sie im Sommer und Herbst aufgrund geringerer Neubildung und höherer Evapotranspiration sinken. Das Ausmaß der Wasserstandsschwankungen kann je nach klimatischen Bedingungen saisonal oder von Jahr zu Jahr stark schwanken. Die jahreszeitlichen Schwankungen werden in den Einzugsgebieten von Wasserwerksbrunnen und Beregnungsbrunnen verstärkt, da aus diesen im Sommer mehr Grundwasser gefördert wird als im Winter und aus letzteren im Winter in der Regel gar kein Grundwasser gefördert wird.
Beispielhafter Verlauf der Grundwasserstände der Messstelle Fuhrberg-Ort mit typischem Jahresgang (Mitte), abhängig von den Jahresniederschlägen (oben) und jährlichen Förderraten des Wasserwerks Fuhrberg (unten). Daten: DWD, NLWKN & Region Hannover. Quelle: BGR
Überlagert werden die natürlichen, klimabedingten Schwankungen des Grundwasserspiegels von den Auswirkungen menschlicher Aktivitäten.
So können beispielsweise eine zunehmende Flächenversiegelung, das Abholzen von Wäldern oder die Trockenlegung von Feuchtgebieten den
Oberflächenabfluss beschleunigen und damit die Grundwasserneubildung verringern. Demgegenüber können landwirtschaftliche Bodenbearbeitung,
das Aufstauen von Bächen, ein klimaangepasster Waldumbau und die Schaffung künstlicher Feuchtgebiete die Grundwasserneubildung erhöhen.
Die langfristige und umfängliche Überwachung der Wasserstände ist die Voraussetzung dafür, relevante und zuverlässige Ergebnisse zu
erhalten und so zum Schutz des Grundwassers beizutragen.
Grundwassermessstelle
Grundwassermessstellen werden hauptsächlich zur Beobachtung des Grundwasserspiegels und der Strömungsverhältnisse, zur Entnahme von
Proben für die Bewertung der Grundwasserqualität und zur Bestimmung der hydraulischen Eigenschaften des Grundwasserleiters eingesetzt.
Sie werden auch als "Beobachtungs-" oder "Überwachungsbrunnen" bezeichnet, aber auch einfach nur als Pegel, Peilrohr oder Piezometer.
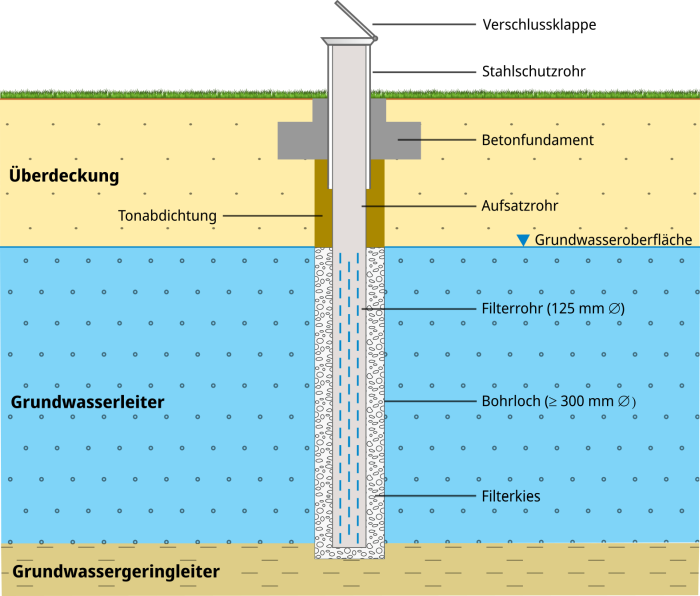
Eine Messstelle besteht in der Regel aus PVC-Rohren mit einem Durchmesser von 5 – 15 cm, die wasserdicht miteinander verschraubt sind.
Die Rohre werden in einem vorher abgeteuften Bohrloch mittels Abstandhaltern mittig platziert. Der oberste Teil der Messstelle, der
Messstellenkopf, endet aus Gründen des Schutzes vor versehentlicher oder mutwilliger Beschädigung möglichst mit einem Stahlrohr und
einer sicher verschließbaren Abschlusskappe. Das Stahlrohr sollte standsicher in einem Betonfundament verankert sein. Handelt es sich um eine Messstelle mit Überflurabschluss, so sollte sie mit einem Anfahrschutz und zur Sichtbarmachung im Gelände mit einer Pegelfahne versehen sein. Der untere Teil der Messstelle besteht normalerweise aus dem Filterrohr, das im Bereich des grundwassererfüllten Teils des Aquifers eingebaut wird.
Der Ringraum um den Filter wird mit Filterkies verfüllt, der Ringraum darüber wird mit Ton oder mit einer Ton-Zement-Mischung abgedichtet,
um das Einsickern von Wasser von der Oberfläche auszuschließen.
Schematischer Aufbau einer Grundwassermessstelle (links), Quelle: BGR sowie Grundwassermessstelle in der Colbitz-Letzlinger Heide (rechts), Quelle: BGR.
Grundwassermessstellen können ebenso wie andere Arten von Brunnen einen Zugang für Wasser schlechter Qualität, Schadstoffe und
Verunreinigungen darstellen. Da sich Überwachungsbrunnen oft absichtlich in Gebieten befinden, die von Verunreinigungen betroffen
sind, stellen sie eine besondere Gefahr für die Grundwasserqualität dar, wenn sie nicht ordnungsgemäß gebaut, gewartet und rückgebaut
werden. Daher gelten für ihren Bau definierte Regeln, wie sie bspw. im DVGW-Arbeitsblatt W 121 "Bau und Ausbau von Grundwassermessstellen"
oder im Merkblatt "Bau von Grundwassermessstellen" des AK Grundwasserbeobachtung festgehalten sind.
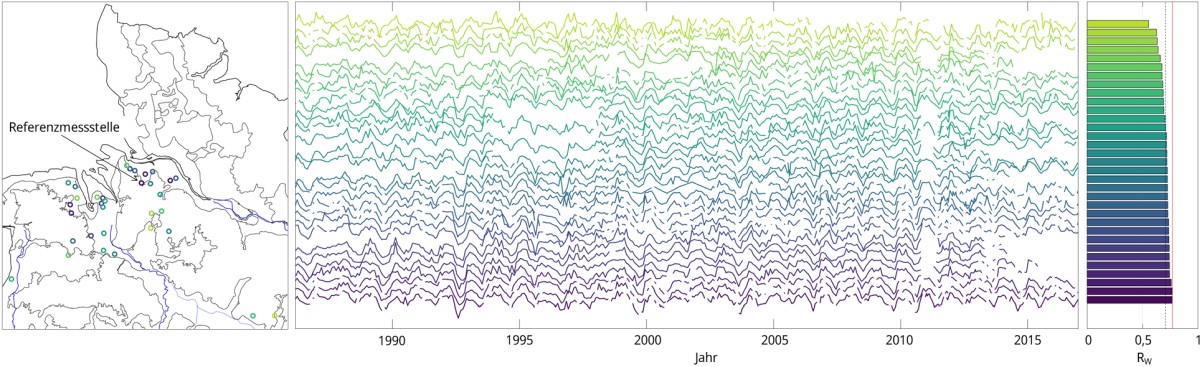
Eine Referenzmessstelle ist bei der hier angewandten Methode der Grundwasserstandsvorhersage eine Messstelle, deren Dynamik für ein Gebiet bzw. Cluster repräsentativ ist, d. h. die Dynamik der Grundwasserganglinie an anderen Messstellen des Clusters verhält sich ähnlich wie an der Referenzmessstelle, so dass z. B. Vorhersagen der Grundwasserstände an der Referenzmessstelle auch auf den Rest des Clusters übertragbar sind. Dies bedeutet jedoch nicht, dass an den Clustermessstellen der gleiche Grundwasserstand in m ü. NN auftritt wie an der Referenzmessstelle.
Zu diesem Zweck wurden die Grundwasserstandszeitreihen mit maximal 12 verschiedenen Merkmalen beschrieben und aus den Daten selbstbeschreibende mathematische Kenngrößen extrahiert, die anschließend Gruppen zugeordnet (geclustert) wurden und Grundwasserganglinien gleicher Dynamik einem gemeinsamen Cluster zuordnen.
Anschließend wurden für jedes Cluster die Ganglinien miteinander korreliert, der Mittelwert des gewichteten Korrelationskoeffizienten Rw für jede Ganglinie berechnet und schließlich die Ganglinien nach abnehmendem Rw sortiert. Die Referenzmessstelle ist in der Regel die Messstelle, die im Vergleich zu allen anderen Messstellen des Clusters die höchste Übereinstimmung hinsichtlich der Dynamik der Grundwasserganglinien aufweist bzw. die im Mittel mit allen anderen Messstellen des Clusters am besten korreliert und gleichzeitig eine sehr gute Vorhersagbarkeit aufweist.
Karte vom Cluster 37 im hydrogeologischen Großraum 1 (Nord- und mitteldeutsches Lockergesteinsgebiet) mit Lage der Referenzmessstelle (links) und gestapelte z-transformierte Ganglinien der entsprechenden Cluster-Messstellen (mittig). Die Farbgebung und die gestapelte Reihenfolge spiegeln die gewichtete Intra-Cluster-Korrelation Rw wider, die auch als Balkendiagramm (rechts) dargestellt ist. Die durchschnittliche Korrelation Rw beträgt 0,71, die höchste Korrelation Rw der untersten Grundwasserganglinie beträgt 0,77. Quelle: BGR & KIT
Das Referenzmessstellenkonzept, d. h. die Reduzierung aller Messstellen auf eine überschaubare Anzahl von Referenzmessstellen, ist dem notwendigen Kompromiss zwischen technischer Machbarkeit und dem Ziel einer möglichst flächendeckenden Vorhersage geschuldet. So kann nur eine begrenzte Anzahl von Messstellen mit Datenloggern plus Datenfernübertragung ausgestattet werden und der Rechenaufwand für die monatlichen Aktualisierungen muss beherrschbar bleiben.
Clustermessstellen sind eine Gruppe von Messstellen, die in der KI-gestützten Grundwasserstandsvorhersage für ein Gebiet bzw. Cluster repräsentativ sind und die sich in der Regel durch eine räumliche Nähe und/oder eine ähnliche hydrogeologische Situation definieren. Clustermessstellen eines Clusters ähneln sich in der Dynamik ihrer Grundwasserganglinien.
Die Clustermessstelle mit einem sehr hohen Korrelationskoeffizienten Rw und gleichzeitig einer sehr guten Vorhersagbarkeit innerhalb eines Clusters ist in der Regel die Referenzmessstelle.
Klima
Klimamodelle sind komplexe mathematische Modelle, die das Klimasystem der Erde in der Vergangenheit simulieren und mögliche Klimaszenarien für die Zukunft berechnen. Sie bilden die Realität nur vereinfacht ab und können das Klimasystem mit seinen verschiedenen physikalischen und chemischen Prozessen nur annähernd wiedergeben. Klimamodelle liefern daher keine Klimaprognosen, sondern nur Klimaprojektionen. Das heißt, sie liefern Aussagen darüber, wie sich das Klima unter den im Modell enthaltenen Bedingungen verändert, also was passiert, wenn sich der Mensch so verhält, wie es im jeweiligen Szenario beschrieben ist.
Klimamodelle enthalten verschiedene Komponenten wie ein Atmosphären- und ein Ozeanmodell sowie weitere Komponenten wie ein Eis-, Schnee- und Vegetationsmodell. Jedes Klimamodell besteht aus einem 3-dimensionalen Gitter, das den gesamten Globus umspannt. Für die zahlreichen Gitterpunkte wird eine Vielzahl von Parametern berechnet. Klimamodelle sind die komplexesten und rechenintensivsten Modelle, die es heute gibt.
Man unterscheidet zwischen globalen Klimamodellen (GCM) und regionalen Klimamodellen (RCM). Globale Klimamodelle umfassen die gesamte Troposphäre und besitzen eine sehr grobe Auflösung von etwa 100 x 100 Kilometern, während regionale Modelle dieselbe Modellphysik nur für einen bestimmten geographischen Ausschnitt der Erde mit einer feinen Auflösung von bis zu 5 x 5 km darstellen. Für Deutschland steht für die drei RCP-Szenarien 2.6, 4.5 und 8.5 jeweils ein DWD-Kern-Ensemble (Version 2018) mit fünf bzw. sechs globalen und fünf bzw. sechs regionalen Klimamodellen zur Verfügung.
Das DWD-Kern-Ensembles wird regelmäßig überarbeitet, um auch neue Klimaprojektionen berücksichtigen zu können.
Klimaszenarien sind Annahmen über die wahrscheinliche Entwicklung des menschlichen Einflusses auf das Klimasystem der Erde und seiner Komponenten wie Temperatur, Niederschlag und Wind. Die Wissenschaft hat in den letzten Jahren eine Vielzahl von denkbaren Szenarien entwickelt, die den Einfluss des Menschen auf das Klima beschreiben.
Diese Szenarien werden in der Wissenschaft auch als "repräsentative" Szenarien (Repräsentative Konzentrationspfade - engl. Representative Concentration Pathways - RCPs) bezeichnet. Die Szenarien beschreiben eine mögliche Zukunft der Weltwirtschaft und der damit verbundenen Treibhausgasemissionen. Sie dienen dazu, die Auswirkungen des Klimawandels auf Umwelt und Gesellschaft zu untersuchen und wurden für den 5. Sachstandsbericht des Intergovernmental Panel on Climate Change (IPCC) entwickelt (siehe RCP-Szenarien).
Repräsentative Konzentrationspfade (RCPs - Representative Concentration Pathways) sind Szenarien, die Zeitreihen von Emissionen und Konzentrationen aller Treibhausgase, Aerosole und chemisch aktiven Gase sowie Landnutzung und Bodenbedeckung umfassen. Das Wort „repräsentativ“ bedeutet, dass jedes RCP nur eines von vielen möglichen Szenarien darstellt, die zu den spezifischen Strahlungsantriebseigenschaften führen würden. Der Begriff „Pfad“ unterstreicht, dass nicht nur die langfristigen Konzentrationswerte von Interesse sind, sondern auch der zeitliche Verlauf, der zu diesem Ergebnis führt.
RCPs beziehen sich in der Regel auf den Teil des Konzentrationspfads, der bis zum Jahr 2100 reicht und für den die integrierten Bewertungsmodelle entsprechende Emissionsszenarien erstellt haben. Dabei beschreibt jedes Szenarium eine mögliche Zukunft und die damit verbundenen Treibhausgas-Emissionen.
Im fünften Bericht des Intergovernmental Panel on Climate Change (IPCC) wurden aus der veröffentlichten Literatur vier RCPs ausgewählt und als Grundlage für die Klimavorhersagen und -projektionen verwendet:
Das RCP-Szenario 2.6 stellt einen Pfad dar, bei dem der Strahlungsantrieb vor 2100 einen Spitzenwert von etwa 3 W/m2 erreicht und dann abnimmt. Dabei würden die Treibhausgas-Emissionen 490 parts per million (ppm) nicht überschreiten und die globale Erwärmung wahrscheinlich unter 2 °C über der vorindustriellen Temperatur gehalten.
Die RCP-Szenarien 4.5 und 6.0 beschreiben zwei intermediäre Stabilisierungspfade, bei denen der Strahlungsantrieb bei etwa 4,5 W/m2 und 6,0 W/m2 nach 2100 liegen wird. Die Treibhausgas-Emissionen würden bis 2100 auf ungefähr 650 ppm bzw. 850 ppm ansteigen.
Beim RCP-Szenario 8.5 handelt es sich um einen hohen Pfad, bei dem der Strahlungsantrieb bis 2100 mehr als 8,5 W/m2 erreicht und bis 2300 auf hohem Niveau bleibt. Die Treibhausgas-Emissionen erreichen 2100 über 1370 ppm. Dieses Szenario wird auch das „Weiter-so-Szenario“ genannt.
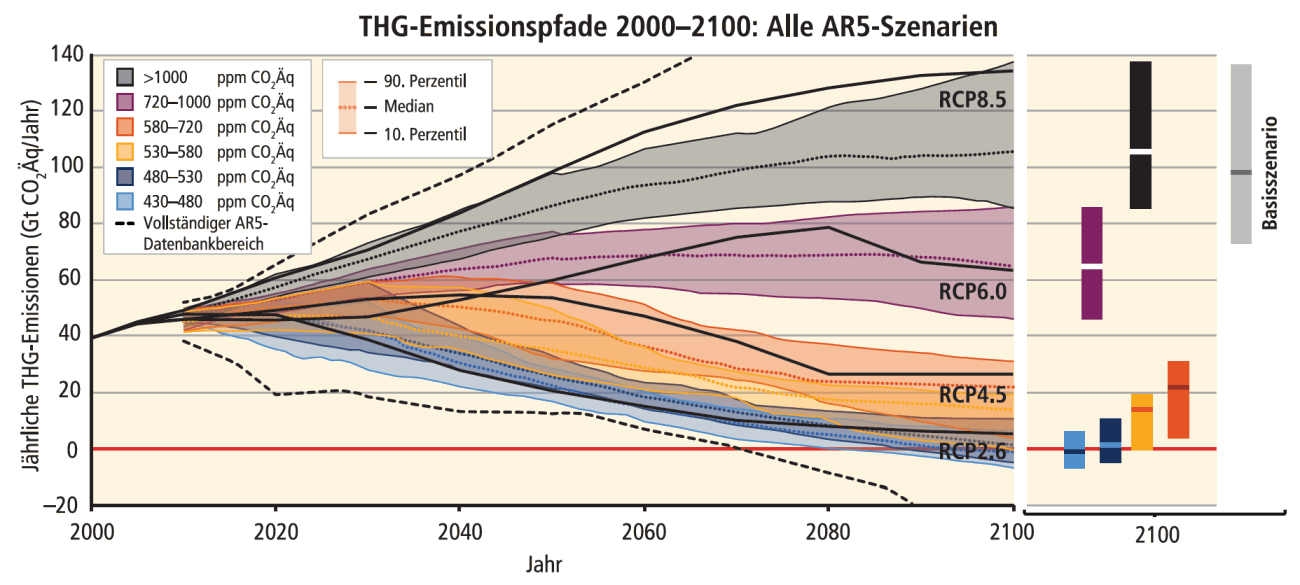
Globale Treibhausgasemissionen (Gigatonnen CO2-Äquivalente pro Jahr, Gt CO2 Äq/a) in Basis- und Minderungsszenarien für unterschiedlich langfristige Konzentrationsniveaus. Quelle: IPCC 2014
Literatur:
IPCC (2014): Klimaänderung 2014: Synthesebericht. Beitrag der Arbeitsgruppen I, II und III zum Fünften Sachstandsbericht des Zwischenstaatlichen Ausschusses für Klimaänderungen (IPCC) [Hauptautoren, R.K. Pachauri und L.A. Meyer (Hrsg.)]. IPCC, Genf, Schweiz. Deutsche Übersetzung durch Deutsche IPCC-Koordinierungsstelle, Bonn, 2016.
Gütemaß
Die Modellgüte ist ein wichtiger Begriff im Bereich der Modellierung. Bei der Modellierung geht es darum, eine mathematische Annäherung für den Zusammenhang von Einflussfaktoren und gemessenen Werten (Zielgröße) zu finden, damit man z. B. Vorhersagen für diese Zielgröße machen kann. Hat man ein solches Modell bestimmt, ist es nun wichtig zu wissen, wie gut das Modell überhaupt funktioniert bzw. wie gut die Vorhersagen mit tatsächlich gemessenen oder beobachteten Werten übereinstimmen. Dazu wird die Modellgüte bestimmt.
Voraussetzung für die Bestimmung der Modellgüte ist die Aufteilung des für die Modellbildung zur Verfügung stehenden Datensatzes. Der Datensatz wird zunächst in einen Trainings- und einen Testzeitraum aufgeteilt. Das Verhältnis dieser beiden Teile ist typischerweise 80 % zu 20 %, kann aber je nach Anwendung und Datenmenge variieren. In unserer Anwendung werden die letzten 3 Jahre der gemessenen Zeitreihe als Testzeitraum verwendet, während der Trainingszeitraum mindestens 10 Jahre beträgt. Die Modellgüte wird dann nur für den Testzeitraum bestimmt. Es gibt viele Methoden und Maße um die Modellgüte zahlenmäßig zu bestimmen, wie z. B. den Mean Absolute Error (MAE), die Nash-Sutcliffe-Effizienz (NSE) oder den Root Mean Squared Error (RMSE). Jedes dieser Maße hat unterschiedliche Vor- und Nachteile, weshalb oft mehrere gleichzeitig berechnet werden. Die zahlenmäßige Bestimmung ist wichtig um Modelle untereinander vergleichen zu können und so das bestmögliche Modell finden zu können.
Die Vorhersagegüte ist wie die Modellgüte eine entscheidende Größe zur Einschätzung eines Modells. Die Vorhersagegüte beschreibt, wie gut ein Modell zukünftige Daten vorhersagen kann. Zur Bestimmung der Vorhersagegüte können verschiedene Methoden bzw. Fehlerkriterien zum Einsatz kommen. Zur Beurteilung der Vorhersagegenauigkeit der eingesetzten Modelle zur Prognose von Grundwasserständen wurden der Bias, die Kling-Gupta-Effizienz (KGE), die Korrelation, die Nash-Sutcliffe-Effizienz (NSE), der Persistency Index (PI), der Root Mean Squared Error (RMSE) sowie R-Quadrat (R2) eingesetzt und berechnet. Diese statistischen Maße werden im Folgenden beschrieben.
Jedes Fehlerkriterium hat Vor- und Nachteile und betrachtet andere Aspekte der Vorhersagegüte, keines lässt für sich allein genommen eine umfassende Beurteilung zu. Aus diesem Grund sollten immer mehrere Fehlerkriterien simultan berechnet und zur Beurteilung herangezogen werden.
Der Bias beschreibt systematische Abweichungen zwischen den Vorhersagen eines Modells und den tatsächlichen Werten, er gibt den mittleren Fehler einer Vorhersage wieder. Die Werte des Bias liegen zwischen \(-\infty\) und \(\infty\). Ein positiver Bias bedeutet, dass das Modell dazu neigt, Werte zu überschätzen, während ein negativer Bias bedeutet, dass es dazu neigt, Werte zu unterschätzen. Ein Bias-Wert von 0 würde ein perfektes Modell bedeuten.
Der Bias wird nach folgender Formel berechnet, wobei \(o_i\) für die beobachteten Werte, \(p_i\) für die vorhergesagten Werte und \(n\) für Anzahl der vorhergesagten Werte steht.
\[Bias=\frac 1n{\sum_{i=1}^{n}(o_i-p_i)}\]
Es ist wichtig zu beachten, dass der Bias zusammen mit anderen Metriken wie dem Root Mean Squared Error (RMSE) oder dem R-Quadrat (R2) betrachtet werden sollte, um ein umfassendes Bild der Leistung eines Modells zu erhalten.
Die Korrelation ist ein Maß dafür, wie stark zwei Variablen miteinander zusammenhängen oder ob es eine klare Verbindung gibt.
Die Korrelation wird oft mit dem Korrelationskoeffizienten R (auch Pearson-Korrelation oder lineare Korrelation) gemessen, der Werte zwischen -1 und 1 annehmen kann. Ein Wert von 1 bedeutet einen perfekten positiven Zusammenhang, was bedeutet, dass die beiden Variablen immer zusammen in die gleiche Richtung verlaufen. Wenn eine Variable steigt, steigt auch die andere und umgekehrt. Ein Wert von -1 zeigt einen perfekten negativen Zusammenhang an, was bedeutet, dass die beiden Variablen immer in entgegengesetzte Richtungen verlaufen. Ein Wert von 0 bedeutet, dass keine lineare Beziehung zwischen den Variablen besteht.
Der Korrelationskoeffizient R wird folgendermaßen berechnet:
Hierbei steht \(o_i\) für die beobachteten Werte, \(\bar o\) für deren Mittelwert, \(p_i\) für die vorhergesagten Werte, \(\bar p\) für deren Mittelwert und \(n\) für die Anzahl der Beobachtungen.
Es ist wichtig zu beachten, dass die Korrelation nur die lineare Beziehung zwischen Variablen misst. Ein nicht bestehender linearer Zusammenhang bedeutet nicht, dass nicht andere Arten von Zusammenhängen bestehen wie z. B. quadratische oder exponentielle.
Die Kling-Gupta-Effizienz (KGE) ist ein Maß für die Vorhersagegenauigkeit von hydrologischen Modellen. Sie hilft zu verstehen, wie gut ein Modell Ergebnisse vorhersagt.
Die KGE-Metrik berücksichtigt drei wichtige Aspekte: die Übereinstimmung in Bezug auf den Durchschnitt, die Übereinstimmung in Bezug auf die Variabilität und die Übereinstimmung in Bezug auf die Korrelation zwischen beobachteten und vorhergesagten Daten.
Dabei steht \(r\) für die Korrelation zwischen simulierten und beobachteten Daten, \(α\) für das Verhältnis der Standardabweichungen von simulierten und beobachteten Daten und \(β\) für das Verhältnis der Mittelwerte von simulierten und beobachteten Daten.
Der beste Wert für die KGE ist 1. Das bedeutet, dass das Modell sehr gute Vorhersageergebnisse liefert und die beobachteten und vorhergesagten Daten in Bezug auf den Durchschnitt, die Variabilität und die Korrelation sehr gut übereinstimmen. Ein niedrigerer Wert für die KGE zeigt an, dass das Modell weniger genau ist und größere Abweichungen in den vorhergesagten Daten im Vergleich zu den beobachteten Daten aufweist. Ein Wert nahe bei 0 oder negativ deutet darauf hin, dass das Modell die Daten nicht gut erklären kann und wenig Übereinstimmung mit den tatsächlichen Beobachtungen aufweist.
Die Kling-Gupta-Effizienz und die Nash-Sutcliffe-Effizienz (NSE) sind Maße zur Bewertung hydrologischer Modelle. Die KGE berücksichtigt Durchschnitt, Variabilität und Korrelation, während die NSE sich hauptsächlich auf Abweichungen vom Durchschnitt konzentriert. Die KGE ist umfassender und liefert detailliertere Informationen zur Modellleistung, während die NSE spezifischer auf die Abweichungen eingeht. Die Wahl zwischen beiden hängt von den spezifischen Anforderungen und dem Kontext der Anwendung ab.
NSE ist die Abkürzung für Nash-Sutcliffe-Effizienz oder auch Nash-Sutcliffe-Effizienzkoeffizient. Die Nash-Sutcliffe-Effizienz ist
ein in der Hydrologie und Hydrogeologie weitverbreitetes Gütekriterium für die Prognosefähigkeit von Modellen und damit ein Maß für die
Modellgüte. Zur Berechnung der NSE werden die Messwerte o (engl.: observed) und die Vorhersagewerte p (engl.: predicted) für einen bestimmten Zeitraum benötigt. Um die Modellgüte nicht zu optimistisch einzuschätzen, sollte dieser Zeitraum ein Zeitraum sein, der nicht zum Training des Modells verwendet wurde. Auf der Grundlage der gemessenen und vorhergesagten Werte wird die NSE nach folgender Gleichung berechnet:
Dabei steht \(m\) für die Anzahl der Werte pro Zeitreihe, \(n\) für die Anzahl vorhergesagter Werte, \(o_i\) für die beobachteten Werte, \(\bar o_i\) für den Mittelwert der beobachteten Werte der Zeitreihe vor dem Vorhersagestart und \(p_i\) für die vorhergesagten Werte.
Der Wert der NSE kann zwischen \(-\infty\) und 1 liegen. Ein Wert von 1 entspricht einer perfekten Modellvorhersage. Werte kleiner oder gleich 0 bedeuten, dass das Modell schlechter abschneidet als eine naive Schätzung, bei der stets der Mittelwert der gemessenen Werte als Vorhersage verwendet wird. Ein NSE-Wert größer als 0 zeigt hingegen an, dass das Modell bessere Vorhersagen liefert als der Mittelwert.
Neben der NSE gibt es weitere Maße zur Einschätzung der Modellgüte, wie z. B. den Bias, den Mean Absolute Error (MAE) oder den Root Mean Squared Error (RMSE).
Der Persistency-Index (PI) wird analog zur oben beschriebenen Nash-Sutcliffe-Effizienz (NSE) berechnet, verwendet aber als Vergleich nicht den Mittelwert der Zeitreihe, sondern eine sogenannte naive Vorhersage. Darunter ist hier der letzte beobachtete Wert vor dem Vorhersagestart gemeint. Der PI wird nach folgender Gleichung berechnet:
Dabei steht \(n\) für die Anzahl vorhergesagter Werte, \(o_i\) für die beobachteten Werte, \(o_{last}\) für den letzten beobachteten Wert vor dem Vorhersagestart und \(p_i\) für die vorhergesagten Werte.
Der PI-Wert kann wie der NSE Werte zwischen \(-\infty\) (sehr schlechtes Modell) und 1 (perfektes Modell) annehmen, wobei alle Werte größer als 0 Vorhersagen beschreiben, die besser sind als der Vergleichswert.
Neben dem PI gibt es weitere Maße zur Einschätzung der Modellgüte, wie z. B. den Bias, den Mean Absolute Error (MAE) oder den Root Mean Squared Error (RMSE).
Der RMSE (Root Mean Squared Error), die Wurzel aus dem mittleren quadratischen Fehler, ist ein Maß das verwendet wird, um die Genauigkeit von Vorhersagen in einem Modell zu bewerten. Es misst die durchschnittliche Abweichung zwischen den vorhergesagten und den tatsächlichen Werten.
Die Berechnung des RMSE erfolgt in mehreren Schritten. Zuerst werden die quadrierten Abweichungen zwischen den vorhergesagten p (englisch: predicted) und den tatsächlichen Werten o (englisch: observed) berechnet. Diese quadrierten Abweichungen werden dann gemittelt, indem sie durch die Anzahl n der Datenpunkte geteilt werden. Schließlich wird die Wurzel aus dem Durchschnitt der quadrierten Abweichungen gezogen, um den RMSE zu erhalten:
Ein niedrigerer Wert des RMSE zeigt an, dass das Modell genauere Vorhersagen macht. Ein Wert von 0 zeigt ein perfektes Modell an. Ein hoher Wert bedeutet dagegen größere Abweichungen zwischen den vorhergesagten und den tatsächlichen Werten. Nach oben kann der Wert bis unendlich steigen. Es ist wichtig zu beachten, dass der RMSE in der gleichen Einheit wie die Zielvariable gemessen wird. Das Ziel ist es, den RMSE so klein wie möglich zu halten, um eine hohe Vorhersagegenauigkeit zu erreichen. Allerdings sollte der RMSE immer im Kontext des Problems und der zugrundeliegenden Daten betrachtet werden.
R-Quadrat (R2), auch Bestimmtheitsmaß der Regression genannt, gibt an, wie gut vorhergesagte Werte zu den beobachteten Werten passen. R2 ist eine dimensionslose Zahl mit Werten zwischen 0 und 1 und ist ein Gütemaß für die Anpassung eines Modells an die Daten.
Ein R2-Wert von 1 bedeutet eine perfekte Anpassung des Modells an die Daten, während ein R2-Wert von 0 bedeutet, dass das Modell keine Vorhersagekraft hat. R2-Werte zwischen 0 und 1 geben an, wie gut das Modell die Daten erklärt. Je höher der R2-Wert, desto besser ist das Modell in der Lage, die Daten zu erklären.
Dabei steht \(o_i\) für die gemessenen Werte, \(\bar o\) für den Mittelwert der gemessenen Werte und \(p_i\) für die vorhergesagten Werte.
Es sollte beachtet werden, dass R2 nicht allein ausreicht, um die Qualität eines Modells zu beurteilen. Es ist daher immer ratsam, auch andere Metriken und Aspekte zu berücksichtigen, um ein umfassendes Bild der Leistung eines Modells zu erhalten.
Statistik
Die absolute Änderung ist eine Kennzahl in der Statistik, die die Differenz zwischen zwei Werten angibt. Sie gibt an, um wie viel sich ein Wert verändert hat. Im Gegensatz zur relativen Änderung hat die absolute Änderung eine physikalische Einheit.
Die Formel zur Berechnung der absoluten Änderung lautet:
\[Abs.~Änderung=Endwert-Anfangswert\]
Die relative Änderung ist ein Maß für die Veränderung eines Wertes im Verhältnis zu einem anderen Wert. Es wird in der Statistik häufig angewendet, um die prozentuale Veränderung zwischen zwei Werten zu berechnen.
Quantile sind statistische Kennzahlen, die häufig in der beschreibenden Statistik verwendet werden, um die Verteilung von Daten zu analysieren und um Zusammenhänge zwischen verschiedenen Variablen zu untersuchen. Ein Quantil definiert einen bestimmten Teil einer Datenmenge, d. h. ein Quantil gibt an, wie viele Werte einer Verteilung über oder unter einem bestimmten Grenzwert liegen.
Dazu werden alle Werte zunächst ihrer Größe nach sortiert und anschließend in gleich große Abschnitte mit gleich vielen Datensätzen untergliedert. Besondere Quantile sind u. a. der Median (50 %-Quantil), das Quartil (25 %-Quantil), das Quintil (20 %-Quartil) und das Perzentil (1 %-Quantil), letzteres unterteilt eine Datenreihe in hundert gleich große Teile.
So gibt z. B. das 2,5-Perzentil an, dass 2,5 % aller Werte eines Datensatzes unter diesem Wert liegen, und das 97,5-Perzentil gibt an, dass 97,5 % aller Werte eines Datensatzes unter diesem Wert liegen. Es handelt sich also um Grenzwerte einer Verteilung.
Methodisches
Wir stellen nur die vorhergesagten Grundwasserstände zum Download zur Verfügung, da wir nicht Eigentümer der Messstellen sind. Die Verantwortung für die Messungen und deren Bereitstellung liegt bei den jeweils zuständigen Länderbehörden. Wir empfehlen, die Grundwasserstandsdaten immer über die Datenportale der Länder abzurufen (siehe Länderdienste).
GRUVO basiert auf dem sogenannten Referenzmessstellenkonzept (siehe Methodik). Das bedeutet, dass alle Messreihen, die uns von den zuständigen Länderbehörden zur Verfügung gestellt wurden, einer Gruppierung bzw. einem Clustering unterzogen wurden. Für jedes Cluster wurde eine Referenzmessstelle definiert, d. h. diese Messstelle ist hinsichtlich ihres Ganglinienverlaufs repräsentativ für alle anderen Messstellen des Clusters.
Hintergrund dieser Vorgehensweise ist die Reduzierung der Rechenzeit und die Vereinfachung des Datenflusses, da nur für die Referenzmessstellen aktuelle Daten benötigt werden. Beim Anklicken einer beliebigen Messstelle eines Clusters werden daher immer nur die Daten der jeweiligen Referenzmessstelle angezeigt.
Aufgrund der sehr heterogenen Aktualität der verfügbaren Grundwasserstandsdaten - für einige Messstellen liegen tagesaktuelle Daten vor, für andere sind die Daten bis zu 20 Wochen alt - und einer einheitlichen Vorgehensweise werden derzeit nur meteorologische Daten und keine Grundwasserstände als Input für die Modellierung bzw. Vorhersage der Grundwasserstände verwendet. Der Sprung ist also in der Regel methodisch bedingt.
Grundwasserstandsganglinie der Referenzmessstelle A1 Altmiks im Cluster GR5_30. Quelle: BGR